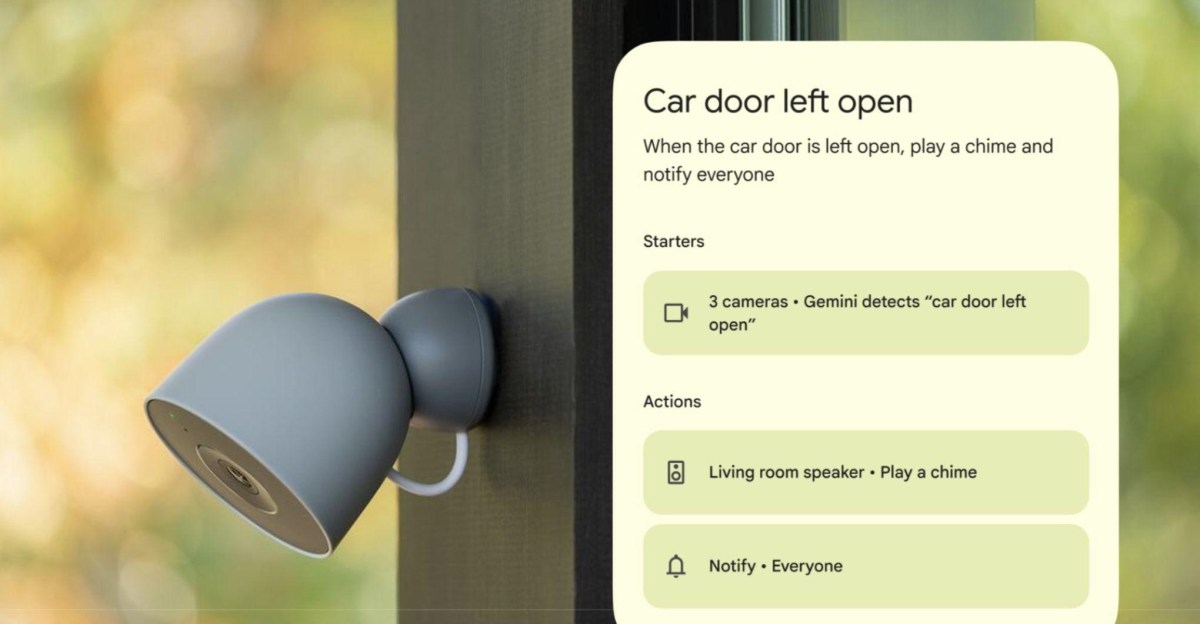
Google Home ahora puede usar cámaras para disparar automatizaciones basadas en visión computada, pero la función está disponible solo en inglés para usuarios de EEUU inscritos en el programa Public Preview y requiere el plan Google Home Premium Advanced (US$20/mes o US$200/año), según el anuncio oficial de Google del 28/5/2026.
Qué anunció Google y cómo funciona
Gemini for Home incorpora una capacidad para que las cámaras “entiendan” escenas y, según la compañía, desencadenen rutinas cuando detectan lo que describimos en lenguaje natural. La función soporta cámaras Nest y ciertas terceras partes con ‘Gemini Built-In’ y permite pedir cosas concretas —por ejemplo, “raccoons near the trash bins”— para activar luces o notificaciones, según el anuncio del 28/5/2026. Google también aclaró que la cámara necesita un “breve momento” para procesar la imagen y que no está pensada para alertas instantáneas ni para reemplazar sistemas de seguridad críticos; esa advertencia aparece en la documentación oficial. El despliegue llega después del early access iniciado en octubre, es decir, aproximadamente siete meses de prueba pública hasta esta ampliación a Public Preview, según la cronología del anuncio.
¿Cómo impacta esto en Argentina?
En la práctica inmediata: poco, porque la función no está disponible fuera de EEUU y sólo en inglés, por lo que los hogares argentinos no pueden acceder a ella en el corto plazo según el anuncio. Para cuando Google la abra más ampliamente, la barrera del idioma y la suscripción serán relevantes; el plan Premium Advanced cuesta US$20 por mes o US$200 por año, un dato clave para evaluar adopción en mercados con poder adquisitivo distinto al estadounidense (según Google, 28/5/2026). Vemos dos problemas concretos para Argentina: la falta de documentación técnica en español y la ausencia de métricas públicas sobre precisión y latencia; sin esos datos será difícil evaluar si la función sirve en barrios con conectividad limitada o con cámaras de menor resolución. Por eso insistimos en documentación en español y métricas públicas antes de su expansión.
Riesgos: privacidad, seguridad y equidad
El sistema procesa imágenes para identificar objetos, vehículos y rostros (con ‘Friendly Faces’ habilitado) y eso introduce riesgos puntuales de privacidad y sesgo en la detección. Google ya señala que no debe usarse para “seguridad y situaciones sensibles”, lo que subraya que hay límites técnicos (latencia y tasa de aciertos) que la empresa no detalló en el anuncio del 28/5/2026. Además, el modelo de negocio basado en suscripción (US$20/mes) plantea un riesgo de equidad: funcionalidades clave ligadas al pago generan brechas entre quienes pueden pagar y quienes no. Pedimos métricas públicas —por ejemplo, tasas de falsos positivos/negativos y latencia promedio en ms— y controles humanos en el loop para minimizar errores antes de que estas automatizaciones formen parte de flujos críticos en hogares.
Qué pedimos y hacia dónde ir
Apoyamos despliegues que vayan acompañados de evaluaciones abiertas, métricas públicas y documentación en español; esa es nuestra posición pública y coherente con notas previas sobre Google. Concretamente pedimos tres cosas: 1) que Google publique benchmarks de precisión y latencia por modelo y por cámara (por ejemplo, falsos positivos/negativos y tiempo de procesamiento), 2) que traduzca y documente en español las guías de configuración y privacidad, y 3) que implemente revisión humana en flujos de decisión para casos sensibles y opciones claras para desactivar el análisis por IA. Si Google quiere escalar esto fuera de EEUU, la compañía debería además comprometerse a auditorías independientes y transparencia sobre dónde y cómo procesa las imágenes. Sin esos pasos, la función puede ser útil para automatismos triviales, pero no está lista para reemplazar decisiones críticas en el hogar.


